Micha Have you read this document? https://support.google.com/webmasters/answer/7440203?hl=en Index Coverage report – Search Console Help Ammon 🎓 The short answer is that the site seems to have a large number of technical issues that need a technical SEO or competent webmaster to look at. Many pages in the screenshot were giving Google 404 errors or timing out, others appeared to be duplicates with stronger ranking signals than the possibly canonical tagged ones, etc. This isn't a job for someone who only knows how to use WordPress, as it requires someone who understands much of the actual technologies involved.
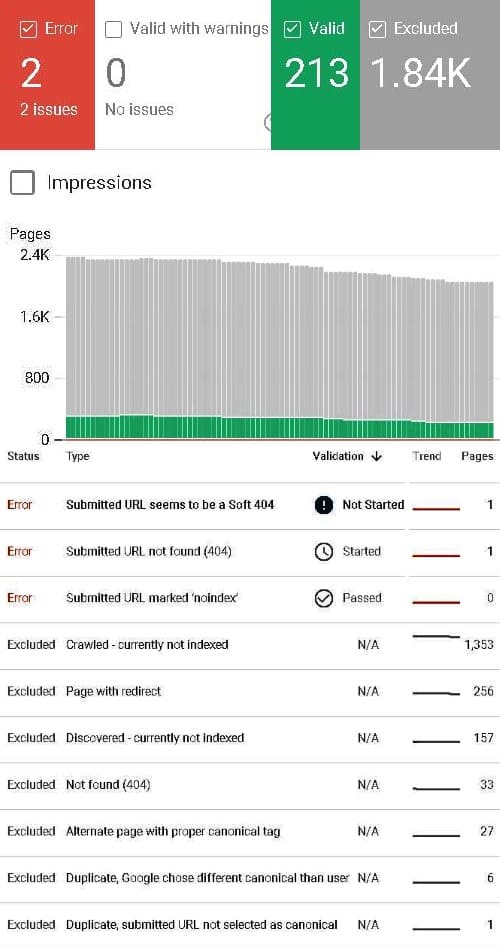
Prakaz ✍️ » Ammon My SEO users have stated that it will take time to improve on the search results as the previous SEO users has messed up the site using the black hat technique. How sure could that be as my site has less than 300 pages indexed and the rest are excluded? Possibly it may not be a one night job where there is a quick fix and I do understand that it will take time. Ammon 🎓 » Prakaz It certainly won't be an instant or overnight fix, given the scope of the site. There are almost 2,000 pages, and for a very large majority of those there seems to be one message above all others – Crawled but not Indexed. That particular message didn't used to be shown to anyone but Google's own engineers, but it isn't new as a situation. It's only new as in they now share that detail instead of just showing the URLs are not indexed. What it generally means is that the crawler, which is the 'bot' part, grabbed your page, but it hasn't been deemed of a high enough quality or importance to actually include in the index. 9 times out of 10, this is a situation where the 'importance' signals of the site are not high, or at least, not high enough. The metrics Google use to determine how important any one page is against all other pages it knows about, are mostly about the links to that site, how connected it is to the big and popular destinations of the web. But the use of brand in searches, where people specifically mention the brand to get that particular viewpoint, also can be a metric. The other metrics are about how important Google believe the topic of the page is to their current users. Is this a trending topic as far as they can tell from the context of links to the page? Is this page likely to be a useful answer that thousands of people will want to see each day, or is this a page likely to be lucky to get one visitor a month who really needs it? Does it seem probable or likely, (based on everything Google know about this site and url), add anything important to users that isn't on the pages Google have already indexed? What genuine backlinks does your 2,000 page site have to justify crawling and indexing all of those pages, when compared with the number of links a good 100 page site can earn? Prakaz ✍️ » Ammon By the justification above, does it mean that the site need genuine links and content acquisition in order for the pages to be user friendly and can be indexed again? Ammon 🎓 » Prakaz Links alone won't fix the technical errors in the site, especially not those where Google couldn't even find the page (404 errors) either because the link was broken, or because the server was timing out. Nor will links fix the duplicate content issues and poor canonicalization. Fixing the tech *might* make the site a bit better and help people feel good about linking to it though. I'm saying that the technical issues need fixing, AND that even once fixed, if Google don't see enough importance to the site, some actual value to THEIR business of better satisfying search users (they don't care what site or page ranks where, only that users find whatever they seek quickly and will gladly use Google again over any rivals). Prakaz ✍️ » Ammon Should these technical issues be looked at by the agency prior to the start off the campaign and bring value to the site by indexing those pages? Ammon 🎓 » Prakaz Yes. Without fixing the technical issues, the foundation of the site, then anything else they do is built on shaky foundations that may have to be torn down, and thus is a waste of time and effort. Jonathan » Ammon That,s right. The most useful thing you could do before you begin any site SEO is the site SEO/technical audit audit. This is because so many other technical aspects are involved with SEO plus a hundred other things. Without addressing this step properly, it's a veritable waste of time that gets you really lost in the world of "it depends". A proper SEO/technical audit with client business goals in mind is the only way to correctly SEO any site that's worth a damn. Oh sure identify and change something in a few minutes that can have major influence on site rankings but big waste of time with site full of SEO/technical errors to begin with. You need a decent base SEO/technical audit with identifiable business goals to consider before you SEO a clients site. Or else its just a bunch of back and forth and time wasted. Duplicate content, canonical issues, major 401 issues. Go with the audit first, Prakaz. Save time and save money!!! Prakaz ✍️ » Jonathan Yes, the site was fully audited when the campaign began in October. All the on site and technical recommendation were given to me and further work were conducted. I'm bit surprised the team didn't notify me about the number of pages that were not indexed until I addressed the issue myself unless they knew within the team. They told me that it was the past SEO users who didn't do the things correctly which led to this issue which they are having a look into and told that it will take time to fix. Probably, I'm thinking they are looking into it. However, how am I suppose to know if the issues are dealt and the changes are being made and should this issue have been resolved in the first/second month of the campaign while the issue is still there showing in the Google Search Console (GSC) Jonathan I really like using a history change tracker like you find with "ContentKing" or "simple history WP plugin". Keeps track of any changes made to the website and by whom. Sounds like you inherited a mess my friend.
Patricia Have you looked at most of the excluded pages to see what they are? You need to start there. Some may be old pages you deleted and didn't redirect, may be deleted tag ages, categories, no index pages, pages Google deem not quality enough to index. Some of my ages that were excluded later, I reindexed them, added some words, changed the date on the article, and there were reindexed.