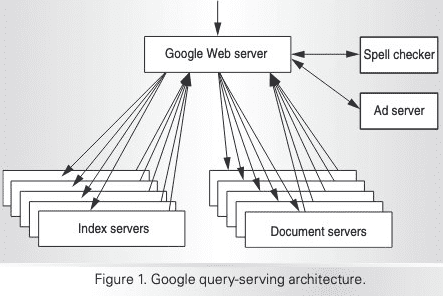
Schieler Mew 👑🎩 "Crawled – Currently Not Indexed" A lot of SEO users are unaware but Google has two server types (See picture below). They have a document server, and an index server, which both serve different purposes. Their document server is where documents (websites) are stored, but not necessarily indexed, and their index server is where documents are queued to show up in the Search Engine Result Page (SERP) (once they have met algorithmic requirements). Regardless of the new search console status of "Crawled – Currently Not Indexed" that's only been around for a year, Google has always used this system. If your websites are not getting pushed into the Index server, here are some things to consider. Is your page really that unique compared to what documents are already provided in the index? Is your page providing something for users that other pages are not? What other page topics have you earned authority on that are in similar clusters to prove you have authority on this pages topic? Writing content and putting it online isn't good enough anymore. What is everyone doing out there to make sure their content serves the best answer and provides something no other indexed documents do? Would love to hear 🙂 139 👍🏽13 💟15417 💬🗨📰👈
Agulto Oh, thanks for the info. This is a very Googly way of handling spinner content. 🙂
Mäkelä » Agulto That's why you see so many people in the Artificial Intelligence (AI) content groups asking why their content is not being indexed. Schieler Mew ✍️ 👑 » Mäkelä Correct. AI content is content that was created, based off content already created. It's adding no additional value. 💟👍🏽2 Dennis » Schieler Mew That's not true at all lol Schieler Mew ✍️ 👑 » Dennis Kirsten Patricio and I tested AI content pretty extensively this year in both our niches. The returned results from Jarvis, showed scraped numbers and addresses from competitors of our clients. Rytr as well. Many others have experienced the same. Unless you take a manual approach of auditing whatever is produced, there is a strong likelihood that there's no additional value being added, and at that point you may as well just write the article yourself. GTP3 scraped the internet to learn its modeling, and it's very apparent. 💟1 Kirsten Patricio 🎓 » Dennis It's actually the case. Any language model learns from what is available out there – similar to how humans learn, which is through modelling, AIs learn from what they can model from and give you an output based on what they learned. It is not capable of producing content just by itself, especially about a subject it hasn't quite learned learned yet. Generative Pretrained Transformer (GPT) is not as advanced and perhaps no where near advanced as Transformer technoiogy is – more than ever now since Google has upgraded Transformer to Reformer which is capable of writing a Wikipedia page on its own. Agulto » Schieler Mew I agree and that is paving the way to article/blog writing to be as difficult as it can be. Hmmm.
Marco That's just a byproduct of how a reverse index works, you have a database with the crawled pages but it doesn't mean your page got sent to the reverse index. It's easier to crawl a page and give it a quality score and if it passes it moves it to the index server. It keeps your page in the database to crawl it again and see if the quality score of your page passes this time to get sent to the indexing server. I have an app with north of 5m user generated products and that's the only way to do a reverse index so you have full search through the document in a reasonable amount of time. And what I do is a simple check of keyword densities along with variations (coding for kazanseo helped with that) and if the product gives me a good score I mark it to be indexed once a week. Daniel I've to disagree. I've seen a lot of shit / palagraised content getting indexed, even on brand new sites
Schieler Mew ✍️ 👑 » Daniel This doesn't make the above false. Google has identified categories for over 4,000 niches. One is not mutually exclusive to the other. The above explains a process that happens for all documents, but doesn't mean that Google wont push a document from the document server to the index server if the algorithms deem it worthy in that niche. 💟👍🏽6
Hogg Interesting. Your diagram shows 4 servers and a spell checker. I find it hard to believe that Google only has 2 server's. 1.Web server 2.Index 3.Documents 4.Ads 5.And a spell checker? If you only tested this on 2 niches, what about the rest of the web?
Schieler Mew ✍️ 👑 » Hogg Hey there, not two servers, two server types. They are daisy Chained together by the thousands for all types. My company houses 5 niches and Kirsten's a singular niche. Seeing this happen in every niche for me was enough for me to ditch it. GTP3 works by scraping the web – as that's how it built its corpora. It makes sense this would happen and without manual human intervention you're just getting scraped and spun content over and over again. Hogg » Schieler Mew Hi, I see I must have misread 😅 I thought Google used a logarithmic scale for page rank etc. When deciding to rank web pages.
📰👈
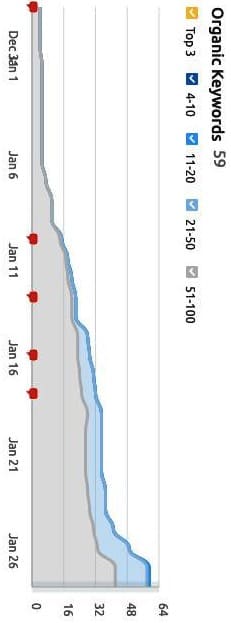
Schieler Mew ✍️ 👑 » Hogg This is part of what helps Google decide if a document gets moved from a document server to a index server, but is not the only attributed signal 🙂 Or in other words, there are two server types, whether or not a document meets Googles algorithmic requirements for that niche determines if it's moved from document storage to the Search Engine Result Page (SERP). Hogg » Schieler Mew I understand, thanks. So how did you test your niches? Schieler Mew ✍️ 👑 » Hogg With AI content or with something else, my friend? Hogg » Schieler Mew Just to work out the 2 server types used. Schieler Mew ✍️ 👑 » Hogg About a year ago we saw a ton of pages we were creating not getting indexed, as we build probably 50k-100k per year for clients. Because I was privy to this information, I began testing different ways of representing information in our niches, as well as scrapped about 5000 results and aggregated the most commonly used bigrams and trigrams, from the top 3 results of every city in America. After I did this, I began rolling out these words into titles and descriptions, as well as making them prominent on pages. In addition, we also did a SERP analysis study with self identified home owners in our niche, in where we measured SERP clicks. I paid particularly close attention to the clicked words as well. What we found was that by using content strategies that supported these commonly clicked and used words, Google was more likely to index our pages quicker. In fact, here's a website we just built at the beg of January with hundreds of pages and it's ranking for a little over 50 keywords (edited) in a moth, with 116 pages picked up as of today. When we started it was a 1 page website. Through our companies tests and studies we were able to begin to figure out how to move pages into the live Search Engine Result Page (SERP) index quicker, when paired with agglomerative clustering, and since, have had no problems with indexing, even in incredibly competitive geo-markets with new websites. You would have to repeat this with each niche, so I can only speak on what's relevant to ours, as it pertains to getting Google to move your content from a document server to an index server.
📰👈
Hogg » Schieler Mew Thanks for explaining your process.
Drake Author ity on those pages is a big one. Another thing you need to look at is internal and external linking, page crawl depth, the basics like mobile friendliness, accessibility, and indexibility. A ton of the pages I see that are not being indexed and should have a combination of those issues. Once you get those addressed, you've got a better chance of getting in the index.
Schieler Mew ✍️ 👑 » Drake Agreed with all points, and this does play a huge role in whether Google decides to move it from their document storage to live SERPs! Umar » Irbaz Just what discussed… Irbaz » Umar Yes
Klok Those are some stark statements. And unless you refer to an official source stating the same, until then I have to call it… you know what. As far as I know, there is not, and never will be an ' exclusion practice' in place.
Schieler Mew ✍️ 👑 » Klok Hey Erik, hope all is well! Googles direct documentation for how their query systems work (repository, barrels, indexer), all discuss this system, and is available publicly in their Google User Content documents. If you or anyone you know has ever built a search engine, even micro, also understands that there is a repository system that stores all associated documents as a cache (Same as Google Cache), and then a system that pulls documents from that Cache into a live SERP, if they meet algorithmic requirements. While this may seem like new information to some, it's pretty standard in search engine modeling! At any rate, Happy Sunday! 💟👍🏽2
Roman Link? URL?
Schieler Mew ✍️ 👑 » Roman Hey there Roman, Google's Stanford paper and documentation discusses how repository, barrels and their indexer systems work. All the above documentation is also available in Google's User Content!🙂
Whyte Great post! I am currently having big issues with this. We sell bolts that have been recategorised into sub cat sizes within the main bolts category (M5 bolts, M6 bolts, M8 bolts etc). Only 2 of 6 of these categories has been indexed. The parent bolts category does not have any products on it, just links to the different size cats 🐈 I have a suspicion of the cause, but I am a bit stuck because I can't really test it as the boss insists the layout stays the same. I'm not sure if anyone will be able to help? The products within these sub categories are in list form, no product images are shown until you click on ‘details' of that particular bolt (eg ‘M5 x 150mm bolt'). Could this be an issue? As the titles of these products are similar and there are not images that differentiate them further? Thanks
Schieler Mew ✍️ 👑 » Whyte Hey bud, is the layout similar to the top 3 results in Google? This is what Google based their "understanding" on, of what a page in the same niche should look/function like at minimum. To beat those pages, you will have to preform analysis and hit all the marks they missed, but generally speaking is the layout the same? Whyte » Schieler Mew Thanks for getting back! The layout (list) is different to the top 3 results, as these all use images. The boss insists it's like this without real reason to change it because that's how he would want to use it as a 65+ year old ex engineer apparently. Is this what you meant? Schieler Mew ✍️ 👑 » Whyte Yes sir! Unfortunately, his opinion is irrelevant to ranking the website. I hate to say that and be so direct, but Google knows exactly what Google wants, based on millions of clicks in your niche and retroactive data modeling. If the top 3 websites all have pictures, and use a specific format, this is the minimum of what should at least be done. Just the way it has to be. I wish I had a better solution for you. Unless you can build some very high authoritative back-links to the pages, Google will always "see" them as less relevant. 🤔1 Whyte » Schieler Mew It's nice to hear that after saying something similar to him! Very stuck in his ways and emotionally attached to the website for various reasons! We have been building authoritative links to the parent cat page but this page isn't even indexed yet after 3 Domain Authorities (DA) 40+ niche relevant links over a couple of months. On a related note – do you think using the same images (for a screw) for every size product (as they're all the same screw) could harm the ‘uniqueness' of the pages? At the moment they're obviously in lists but could be good to know. I appreciate your time here. Got tagged in this post and just came across another one and they're brilliant. Thank you. Schieler Mew ✍️ 👑 » Whyte The same image, if it is the same screw should be perfectly fine as long as your image names and alt tags vary. This will be the differentiating factor. Make sure to include the actual dimensions of the screw in both 💟👍🏽2
Guzman Guys, Google does not just have "two server types", that's not right, please document yourself better before you post something like that. Google has thousands of servers grouped in clusters. Within this infrastructure run different algorithms and the process of indexing, rendering, parsing, querying, ranking etc. a website is much more complex. https://developers.google.com/search/docs/beginner/how-search-works "Crawled – Currently Not Indexed" Means that your web page has been discovered and is in the indexing phase. If it earns a ranking position in relation to a search query, then the ranking processing begins, if not, then your pages need better content. DEVELOPERS.GOOGLE.COM Как работает Google Поиск (информация для начинающих) | Центр Google Поиска | Google Developers
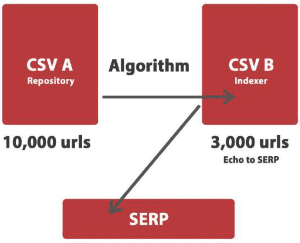
Schieler Mew ✍️ 👑 » Guzman Google absolutely has two server types. I don't think anyone said or asserted, they only have two server types, however we're discussing the two server type clusters that pertain to how rank is distributed. They also have barrel servers, corpora servers, url servers, and more. The only assertion that the above is stating is that Google has two server types they use (in conjunction with many others), that cache the entire internet on one server, and only pull it into the indexing server if it meets algorithmic requirements. If it doesn't meet those requirements (which varies by niche, and year) then it stays in the document servers, and doesn't get copied over to their indexer (SERP) servers. Here's a picture directly from their Stanford papers, in which the repository is the caching system and server where all docs are stored, and the indexer another system that pulls out of the repository when algorithmic requirements are met, then sorted to a barrel server, and sent to the searcher. Thanks for the conversation and adding additional clarity to the overall conversation! Schieler Mew ✍️ 👑 » Guzman Or in more simplified terms, as I have built search engines. You have CSV A and CSV B. CSV A contains all urls, CSV B only contains the urls that meet programmed algorithmic variables. Then CSV B echos to the actual search engine. This image should help!
Morgan You're correct, Schieler. I've always touted for years, the importance of being crawled. Whenever people say I'm not indexed, I ask if they're being crawled. In which in response is as if it's a strange question. As if the two are different factors. Classic or basic Search Engine Optimization (SEO) still works well as an indexing factor or to get on Google for sure. I guess you already knew this. 💟1